頂点座標と法線でObjファイルを描画する
概要
最終更新日:2020/02/11
Objファイルを読み込んで最低限の情報で描画をする方法を書いた記事です。
主に次の項目に該当する方に向けて書いています。
- Objファイルの読み込みの流れを知りたい
- Objファイルの描画の流れを知りたい
- まずはObjファイルの描画をしていみたい
サンプル
サンプルはここからダウンロードできます。
環境は以下の通りです。
開発環境
| VSのバージョン |
DirectXのバージョン |
| VisualStudio 2019 |
DirectX11 |
描画に必要な情報
Objファイルにはいくつもの情報が含まれていますが、描画のために最低限必要な情報は
「頂点座標情報」と「面情報」です。
これだけあればメッシュの描画ができます。
しかし、3Dモデルとしての立体感は表現できません。
立体感を表現するためには「法線情報」を含める必要があります。
マテリアルの反映やテクスチャを使ったUVマッピングなどは別記事で行っていますので、
まずはObjファイルの読み込みと描画の流れを理解してもらえればと思います。
※読み込み方やサンプルでは最適化は一切行っていません。
読み込み方法
Objファイルは1行1行で情報が区切られているので、行単位で読み込みを行います。

行の取得
1行を取得する方法はC言語のfgetsやC++言語のgetlineなどあります。
while (fgets(buffer, LineBufferLength, fp) != nullptr)
{
取得した行の中身を解析していく
}
他にはfscanf_sなどを使用する方法もあります。
while(!feof(fp))
{
// 先頭の情報を取得する
fscanf_s(fp,"%s ", 情報格納バッファ、 バッファのサイズ);
// 取得した内容のチェック
if (頂点座標)
{
// x軸、y軸、z軸を取得
fscanf_s(fp,"%f %f %f",&vx,&vy,&vz);
}
else if (法線)
{
// x軸、y軸、z軸を取得
fscanf_s(fp,"%f %f %f",&nx,&ny,&nz);
}
}
どの手法を使用しても構いませんので、各行の解析を行えるようにします。
先頭の文字列を調べる
1行読み込んだら、読み込んだ行の先頭の文字列に注目してください。
その行がどのような情報になっているかは、先頭の文字列で表されています。
 今回使用する「頂点座標情報」「法線情報」「面情報」は「v」「vn」「f」です。
今回使用する「頂点座標情報」「法線情報」「面情報」は「v」「vn」「f」です。
使わない要素は無視する
Objファイルには様々な情報が含まれていますが、
どれを使うかは開発側次第なので、使用しない情報は無視します。
while (1行取得)
{
v、vn、fなど、使う情報だけ解析する
}
頂点座標情報、法線情報の解析
頂点座標と法線はX軸、Y軸、Z軸の値が「スペース」で区切られており、
Z軸の値の後ろの文字は必ず改行文字になっています。
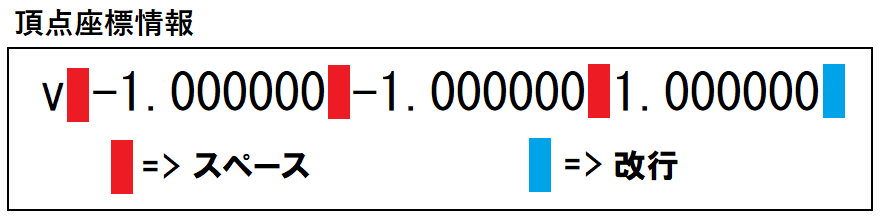 これらをスペース単位で文字分解を行ったり、fprintfで一括で取得したりします。
これらをスペース単位で文字分解を行ったり、fprintfで一括で取得したりします。
std::vector<std::string> split_strings;
// Splitは指定した単位で文字列を分解してくれる自作関数です。
Split(' ', buff, split_strings);
int count = 0;
float values[3] = { 0.0f };
for (std::string str : split_strings)
{
values[count] = atof(str.c_str());
count++;
}
data.push_back(Vector3(values[0], values[1], values[2]));
解析して出た結果の値は頂点座標と法線は面情報の解析時に使用するので、
Vectorなどを使用して別々に保存しておきます。
面情報の解析
面情報は面を作成するために必要な頂点座標情報、UV情報、法線情報が書かれています。
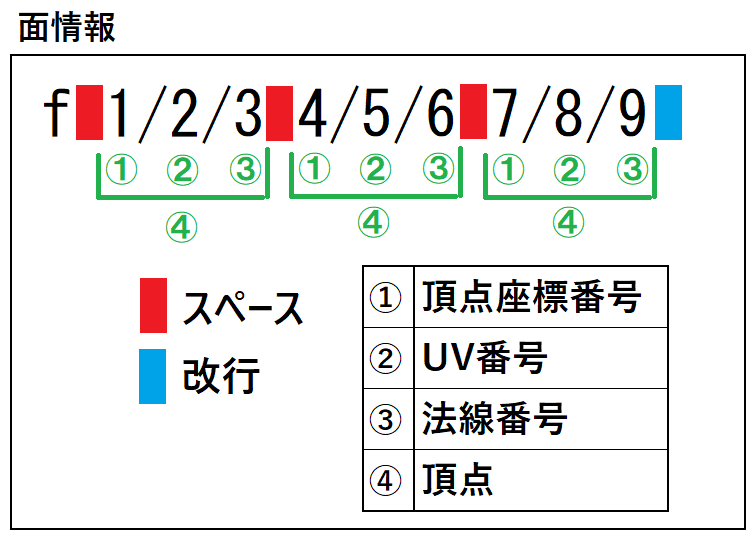 上の図のように面を作るための情報は「/」と「スペース」で区切られており、
頂点座標などの情報は番号で書かれています。
上の図のように面を作るための情報は「/」と「スペース」で区切られており、
頂点座標などの情報は番号で書かれています。
 この番号はvやvnに割り振られている識別番号で、法則はファイルを上から順番に設定されています。
この番号を元にして頂点バッファとインデックスバッファを作成します。
この番号はvやvnに割り振られている識別番号で、法則はファイルを上から順番に設定されています。
この番号を元にして頂点バッファとインデックスバッファを作成します。
void ObjFile::ParseFKeywordTag(std::vector<CustomVertex>& out_custom_vertices, std::vector<Vector3>& vertices, std::vector<Vector3>& normals, char* buffer)
{
int count = 0;
int vertex_info[3] =
{
-1, -1, -1,
};
std::vector<std::string> space_split;
// スペースで文字列を分解する
Split(' ', buffer, space_split);
for (int i = 0; i < space_split.size(); i++)
{
CustomVertex vertex;
// 「/」で文字列を分解する
ParseShashKeywordTag(vertex_info, (char*)space_split[i].c_str());
for (int i = 0; i < 3; i++)
{
if (vertex_info[i] == -1)
{
continue;
}
int id = vertex_info[i];
switch (i)
{
case 0:
vertex.Position = vertices[id];
break;
case 2:
vertex.Normal = normals[id];
break;
}
}
// 作成した頂点情報を追加する
out_custom_vertices.push_back(vertex);
// インデックスバッファに追加した頂点情報の配列番号を追加する
m_Indices.push_back(out_custom_vertices.size() - 1);
}
}
これでメッシュの準備は終わったので、あとはこの情報を使用して描画を行います。